
Lately I was working on a fairly advanced allocation algorithm on large data which forced me to search for different tricks to improve performance than those that you can find on my site here already.
Background
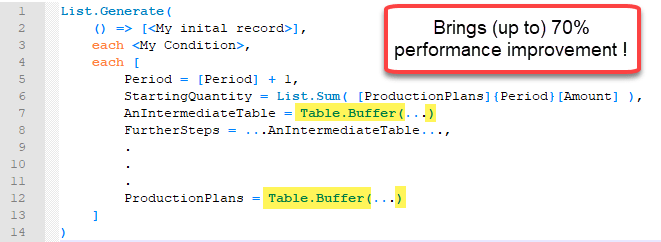
I was using List.Generate to check for every month in my table, if there was enough free capacity on a platform to start new wells. As every well had a certain production scheme (producing different amounts for a certain length of time), I first had to check the total production amount of active wells before I could determine the spare capacity for a new month. So I had to look into every active well, grab the capacity of the new month and add it up.
Therefore I’ve stored the active production schemes in one table in my List.Generate-record. That lead to an exponentially decreasing performance unfortunately.
Solution to improve performance of List.Generate
Buffering my tables in the “next”-function reduced the query duration by almost 70% !
Although a Table.Buffer or List.Buffer is always high on my list when it comes to performance issues, I was fairly surprised to see that behaviour here: As List.Generate returns the last element of its list as an argument for the next step, I was always assuming that this would be cached (and that was the reason because List.Generate performs recursive operations faster than the native recursion in M). Also, I had just referenced that table once ane in such a case, a buffer would normally not have come into my mind. (But desperation sometimes leads to unexpected actions …)
I also buffered a table that had just been referenced within the current record (and not recursively) and this improved performance as well. (Although in that case, the tables has been referenced multiple times within the current record). But this buffer didn’t have such a big impact on performance than the one on the table that was referenced by the recursive action.
Code
Here is some pseudo-code illustrating the general principle:

Solution with buffers:

How to improve performance of List.Generate: Use Table.Buffer
Is that new to you or have you made the same experience? Which grades of performance improvements did you achieve with this method? Please let me know in the comments!
Enjoy & stay queryious 😉
Hi Imke! I think this performance boost is because the ‘promises’ that were generated inside List.Generate or List.Accumulate, something like Gil Raviv described in his post about CamelCase. Buffering forces evaluation and stops stacking of promises, which frees available memory.
But, of course, I could be very wrong.
Thanks Maxim for this hint! https://datachant.com/2018/02/14/split-camelcase-headers-m/
Although I must admit that I don’t understand how it exactly works to “…force the let member to be evaluated inside the function body.”
… so if you feel that it’s time to write a new blogpost, I wouldn’t mind if this was your topic 😉
Cheers, Imke
It is hidden for me too 🙂 as far as I can see, comparing to null forces this evaluation, but… too much for me.
“let’ expression is also a record, so I suppose that it is the same case as yours. But who knows, we need to cast Curt here 🙂
Hi Imke
I’m struggling with the performance in one of my PowerPivot workbooks and I’m wondering if table.buffer could decrease the time it takes to update.
So I have a very large csv-file (roughly 330 MB) that contains my fact table (about 4 million rows). One of the columns in that table is a date column. After I’ve loaded this table I want to create a dynamic date (dimension) table that starts at the earliest date in the fact table and ends at the last date in the fact table. The problem is that my current queries seems to load the large csv-file at least twice.
So this is my current set up
FactTable:
Let
Source = Csv.Document(“…\LargeCSV.txt”)…,
SomeTransformations = Table.Transform…
FilterRows =Table.SelectRows(SomeTransformations,…)
FinalFactTable = Table.AddColumns(FilterRows…)
in
FinalFactTable
DateTable
Let
Source = CreateDateTableFunction()
in
Source
CreateDateTableFunction
let CreateDateTable = () as table =>
let
StartDate = List.Min(Table.Column(FactTable,”Date”),
EndDate = List.Max(Table.Column(FactTable, “Date”),
DayCount = Duration.Day(Duration.From(EndDate – StartDate)),
ListDays = List.Dates(StartDate,DayCount,#duration(1,0,0,0)),
TableFromList = Table.FromList(ListDays…),
FinalDateTable = Table.AddColumn(…),
in
FinalDateTable
in
CreateDateTable
Could I use table.buffer to speed up the update process and if so how would i do that? Do you see any other areas that could improve the performance?
Hi there,
you really have to try this out. Use Process Monitor to check how often the csv has been read: https://blog.crossjoin.co.uk/2018/07/19/using-process-monitor-to-find-out-how-much-data-power-query-reads-from-a-file/
Start with buffering your first step in your FactTable and then the last step.
It can also help to write the start- & end-date of your date dimension to an Excel-Sheet and then re-import it (but that would mean that you have to manually refresh the queries after another (you can put them into different groups and then refresh Group 1 before refreshing Group 2)
Cheers, Imke
I write my start and end dates as separate queries, drill down on each. Then reference them in your date table. {StartDate..EndDate}
Pingback: Buffer your tables in Power BI and Power Query – The BIccountant
Hi Imke,
I have a csv file of 27MB and when I am doing some transformation along with pivot( have not used any aggregate function which i found from your blog(https://www.thebiccountant.com/2020/05/17/performance-tip-speed-up-slow-pivot-in-power-query/#more-8819) .
And then I need to use nextrow of one column to find the gap here again I got help from your post (https://www.thebiccountant.com/2018/07/12/fast-and-easy-way-to-reference-previous-or-next-rows-in-power-query-or-power-bi/) as Index method was too slow for this heavy file.
My challenge is I see my file is loading loading 54MB where as the size is 27MB unable to find why, I have used Table.Buffer() function few place but it still remains same.
So I am still trying to find the pattern where we can use (like if we do lookup between two table we use Table.Buffer() to stop the file loading again and again). So which are the functions where we can put Table.Buffer/List.Buffer. Is there any list of function you can point out.
Hi Mukesh,
to my experience you have to be prepared that your sources will be read twice. Once for the engine to generate the query plan and another one to execute it, unfortunately.
/Imke
Imke, you have just saved me so many additional hours/days of fruitless effort. A very simple query with only 29 interations couldn’t make it past 5 iterations before spinning for what seemed to be hours (although I never let it actually run that long).
With your tweak above, it finished entirely in literally less than 10 seconds! So 70% was a very conservative estimate of the performance gains (in my case) although OMMV.
Thanks so much for posting this. I spent the all day (and probably would’ve the rest of the week) trying to figure out if there was something wrong with my code that was causing the problem.
Microsoft documentation is really pathetic at best. No big surprise there, of course. :-/
Very pleased to hear, WT, so thanks for sharing your experience 🙂
99% improvement.
thank you so much
Pingback: Tables in Power Query - how, when and why | THE SELF-SERVICE-BI BLOG
Pingback: Tables in Power Query - how, when and why | THE SELF-SERVICE-BI BLOG