
Today I’ll present an adjustment to the Text.SplitAny – function in Power BI’s query editor or Power Query. The native function takes a string as an input and splits the text by every character that is contained in the string. This seems fairly unusual to me and I haven’t used that function very often.
Problem
But what I have come across fairly often is the requirement to split a string by a bunch of different (whole) strings (instead of single characters).
Solution
Therefore I’ve modified the native Text.SplitAny – function so that it also accepts lists with strings as its second parameter:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| let func = | |
| (string as text, separator as any) => | |
| let | |
| /* Debug parameters | |
| string = "Do I need gloves for Power Query?", | |
| separator = {"s", "need ", "Do ", "?", "g", "for "}, | |
| */ | |
| SeparatorIsTypeList = Value.Is(separator, type list), | |
| ListFunction = List.Accumulate(separator, | |
| {string}, | |
| (state, current) => | |
| let | |
| DoForEveryItemInTheList = List.Transform(state, each Text.Split(_, current)), | |
| FlattenNestedList = List.Combine(DoForEveryItemInTheList), | |
| RemoveEmpties = List.Select(FlattenNestedList, each _<>"" and _<>" ") | |
| in | |
| RemoveEmpties | |
| ), | |
| TextFunction = Text.SplitAny(string, separator), | |
| Result = if SeparatorIsTypeList then ListFunction else TextFunction | |
| in | |
| Result , | |
| documentation = [ | |
| Documentation.Name = " Text.SplitAnyNew ", | |
| Documentation.Description = " Splits text to a list by each delimiter. Delimters can either be each character from a string or each string from a list. ", | |
| Documentation.LongDescription = " Splits text to a list by each delimiter. Delimters can either be each character from a string or each string from a list. ", | |
| Documentation.Category = " Text ", | |
| Documentation.Source = " https://wp.me/p6lgsG-Yr . ", | |
| Documentation.Version = " 1.0 ", | |
| Documentation.Author = " Imke Feldmann: www.TheBIccountant.com: https://wp.me/p6lgsG-Yr . ", | |
| Documentation.Examples = {[Description = " See this blogpost: https://wp.me/p6lgsG-Yr ", | |
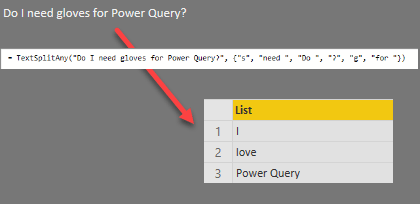
| Code = " TextSplitAnyNew(""Do I need gloves for Power Query?"", {""s"", ""need"", ""do"", ""?"", ""g"", ""for""}) ", | |
| Result = " {""I"", ""love"", ""Power Query""} "]}] | |
| in | |
| Value.ReplaceType(func, Value.ReplaceMetadata(Value.Type(func), documentation)) |
How it works
This new function checks if the 2nd parameter is of type text and if so, applies the native function. But if it’s not text but a list with strings, it applies a different transformation instead, that:
- Walks through the list of separators, using the List.Accumulate-function (row 13)
- Splits the text by every separator in that list (row 17).
- But as the result of a splitted text is a list, this operation has to be performed on every item of that list. Hence I’m using List.Transform for it. List.Transform also walks through every item of a list and does a transformation on it, like List.Accumulate. But it doesn’t feed it’s results of every iteration step to the subsequent step: Instead it simply stores each transformed list element on its original position and returns it there at the end. So while List.Accumulate can return a result of any format (depending on the function you perform in it), List.Transform will always return a list of the same length than the one you feed it.
- Flatten the nested list before the next iteration (row 18).
- When you successfully split each text-item of a list (into a list), you end up with a nested list. But this is not the ideal shape for further transformations. So I flatten the nested list into a simple list for the next iteration-round.
- Gets rid of any empty fields that might have been created by the splitting operation above (row 19)
Hope you enjoy & stay queryious 😉
Hi,
Will the query below achieve the same result as your function or is there a situation where your function achieves a different result? I can’t seem to find a case where the outcomes aren’t the same. I’m curious because I’ve read List.Accumulate isn’t the most efficient function and should be avoided when possible.
let
fnTextSplitAny = (string as text, separator as any) =>
let
TypeListSplit =
let
fnSplit = Splitter.SplitTextByAnyDelimiter(separator),
InvokeSplit = fnSplit(string),
RemoveBlanks = List.RemoveItems(InvokeSplit, {“”, ” “})
in
RemoveBlanks,
TypeTextSplit = Text.SplitAny(string, separator),SplitCondition =
if Value.Is(separator, type list) = false
then TypeTextSplit
else TypeListSplit
in
SplitCondition
in
fnTextSplitAny
Thank you Jason,
your code is looking good – thanks for sharing!
/Imke
Good technical post. We can learn new thing from this post. Keep sharing more good informative blogs. https://fairfaxvirginiaduilawyer.com/fairfax-dui-lawyer/
Excellent post. Keep posting such kind of info on your page. I am really impressed by your blog. Hi there, You have done an excellent job. I will definitely it and in my view suggest to my friends. I am sure they will be benefited from this website.